提到网页得分,相信很多做过性能的前端同学,也都有用过 Lighthouse (opens new window) 的性能评分。
而在更复杂的业务场景下,类似 Lighthouse 这样的工具只能提供打开相关的性能数据。对于重度使用的前端网页来说,或许我们还需要更详细的参考标准。
# Lighthouse 性能得分
其实我们之前在《前端性能优化--数据指标体系》一文中也有介绍常见的前端性能指标,并提到 Google 的 PageSpeed Insights (PSI) (opens new window) 网页性能指标体系。
简单来说,PageSpeed Insights 可同时获取实验室性能数据和用户实测数据,而 Lighthouse 则可获取实验室性能数据以及网页整体优化建议(包括但不限于性能建议)。
而我们通过阅读 Lighthouse 官方文档,也能知道 Lighthouse 的评分标准。以 10 号灯塔 (opens new window)为例,其评分加权为:
| 评分点 | 权重 |
|---|---|
| First Contentful Paint(FCP,首次内容渲染) | 10% |
| Speed Index(速度指数) | 10% |
| Largest Contentful Paint(LCP,最大绘制内容) | 25% |
| Total Blocking Time(TBT,总屏蔽时间) | 30% |
| Cumulative Layout Shift(CLS,累计布局偏移) | 25% |
Lighthouse 收集性能指标(大多数以毫秒为单位报告)后,会根据指标值在 Lighthouse 评分分布中的所处位置,将每个原始指标值转换为 0 到 100 之间的指标得分。评分分布是基于 HTTP 归档中真实网站性能数据的性能指标派生出来的对数正态分布。
相比 Lighthouse,PageSpeed Insights (PSI) 根据网页指标计划设置了阈值,并选择了所有指标的第 75 百分位,将用户体验质量分为三类:良好、需要改进或较差。
但对于复杂的应用页面,这些指标都无法足够衡量用户的整体体验。我们通常会在首屏加载完成的时机将一些打开指标数据进行上报,但这依然会有个问题:用户在后续使用过程中的性能和质量情况是否可以关注到?
因此我们可以借鉴 Lighthouse 和 PSI,自行根据业务的具体问题和使用场景,提出复杂网页的质量得分定义。
# 复杂网页质量得分
复杂的前端应用不多见,在我的文章里,经常提到的无非是游戏和在线文档两种。和以往一样,我们同样以在线表格为例子,来定义复杂页面的质量得分。
或许我们在日常工作中,很多时候都是点对点地跟进性能问题,并没有再进一步地进行归档整理和体系化建设。但这样的模式会让我们一直处于被动,等到用户反馈问题、投诉卡顿等,其实已经比较滞后了。
而对于线上的大盘数据中,到底还有多少用户的使用体验其实并不好,但没能反馈到开发者手上呢?这样的用户占比是怎样的,又是什么原因导致他们的使用体验很差呢?
因此,我们基于以上的思考,来尝试定义网页质量得分:
- 打开场景,主要为打开流畅度、响应速度等等。其实也是 PSI 里面的指标,包括 CLS、FID、LCP、INP、FCP、TTFB。
- 使用场景,主要包括卡顿情况、页面滚动流畅度、用户交互等待耗时等等。除了卡顿、FPS 等指标,剩余的则是跟业务强相关的指标定义了。
我们可以这样设计网页的质量得分,那么该质量得分数据会以以下方式呈现:
- 首次产生得分:首屏/首表加载相关性能数据获取完毕,根据各种指标(CLS、FID、LCP、INP、FCP、TTFB)计算得分,并跟随这些数据进行统一上报。
- 使用过程中分数变化:当用户在继续浏览和操作网页时,根据产生卡顿的次数/卡顿耗时、页面 FPS 流畅度、特定用户操作的等待耗时等等,以扣分的方式进行得分计算。当得分下降较严重时,将相关数据一并进行上报。
# 数据如何上报
已知质量得分分成打开过程和持续使用过程,有两种方式进行得分的上报:
- 统一时机上报。如果需要计算单次访问质量情况,更适合在某个统一的加载时机,将上述涉及的性能数据一起进行上报。这种方式更适合将这些数据进行聚类和二次分析,但问题在于用户在后续使用过程中,可能会突然关闭页面,导致数据未能及时上报。
- 多次数据分别上报。
多次上报(不同上报时机)的数据,如果需要聚合在一起进行分析,则需要关联到同一篇网页内容、甚至是同一次访问会话中,这种情况下:
- 相关指标每次上报时,都需要关联到内容 id(考虑是否存在数据隐私问题)
- 使用的数据平台需要支持数据二次聚合(先将多次访问数据以单篇内容为维度进行汇总,再以单篇内容作为基础颗粒度进行数据的二次计算,得到最终数据看板)
# 得分上报时机
一般来说,我们希望关注用户的整体使用过程,则可以考虑两个阶段上报:
- 在首屏数据加载完成时,根据打开指标计算得到一个得分,并进行上报。
- 在打开阶段得到一个初始分数后,会基于此得分进行后续的计算,在页面
beforeunload前,将初始得分、扣除分数、运行时长、生命周期信息、最终得分等进行上报。
但在实际项目中验证发现,beforeunload下的上报数据对比首表加载完成,转化率不到 10%,因此需要考虑使用其他上报时机。
因此,我们可以调整方向,使用其他方式来进行得分上报:
- 达到一定扣分阈值时,进行上报。
- 按停留时间上报,则需要配置定时器进行定时上报(可能会出现上报量过大的场景)。
不管是哪种方式,我们还需要考虑一个问题:假设每次扣分都进行上报,那么要如何将多次的上报关联到一次,并认为是同一个会话过程产生的,进行去重获取最后的得分?
答案也挺明显简单的:使用每次访问的唯一会话 id 进行去重过滤。
使用扣分机制的好处是,我们针对相同会话中的多次上报,只需要取最小得分,便可得到该过程中用户的具体扣分情况,以此来得到本次网页的访问体验得分。
# 质量得分建设
当我们尝试给一个页面定义质量得分时,很难一开始就能给到完整各种维度的指标定义和参考值。因此,为了跑通该指标体系,我们可以分阶段进行:
- 定义初步指标评分体系,跑大盘数据观察数据。
- 根据用户体验新增或调整指标,逐渐贴近用户真实感受。
- 指标稳定后,分析待提升质量的网页特征,进行特征优化。
# 初步得分建设
假设我们现在仅参考几个指标,还是以在线文档编辑的场景为例,以以下三个核心指标作为初步指标:
| 指标名称 | Good | Needs Improvement | Poor | 得分占比 |
|---|---|---|---|---|
| 首屏可见耗时(ms) | (0, 1800] | (1800, 2500] | > 2500 | 30% |
| 首屏可交互耗时(ms) | (0, 2950] | (2950, 4000] | > 4000 | 40% |
| 首屏可编辑耗时(ms) | (0, 5000] | (5000, 8000] | > 8000 | 30% |
| 得分 | (100, 80] | (80, 60] | (60, 0] |
以上只是初步最简单的定义,具体实践时可以调整或新增,比如全文档可编辑耗时、卡顿情况等等都可以统计进去。
举个例子,假设一篇文档的加载耗时分别为:
| 指标名称 | 指标数值 | 计算得分 | 得分 |
|---|---|---|---|
| 首屏可见耗时 | 2000 ms | = 80 - (2000 - 1800) / (2500 - 1800) * (80 - 60) | 74.29 |
| 首屏可交互耗时 | 3000 ms | = 80 - (3000 - 2950) / (4000 - 2950) * (80 - 60) | 79.05 |
| 首屏可编辑耗时 | 6000 ms | = 80 - (6000 - 5000) / (8000- 5000) * (80 - 60) | 73.33 |
| 总得分 | = 74.29 _ 30% + 79.05 _ 40% + 73.33 * 30% | 75.91 |
那么,这篇文档的得分是 75.91 分。
# 大盘数据建设
现在,我们有了每篇文档的得分,那么针对每篇文档得分大盘数据就有了参考意义。我们可以针对每篇文档的得分,捞取出服务质量不好的文档并进行分析。
举个例子,我们可以建立一个大盘表格服务质量占比看板:
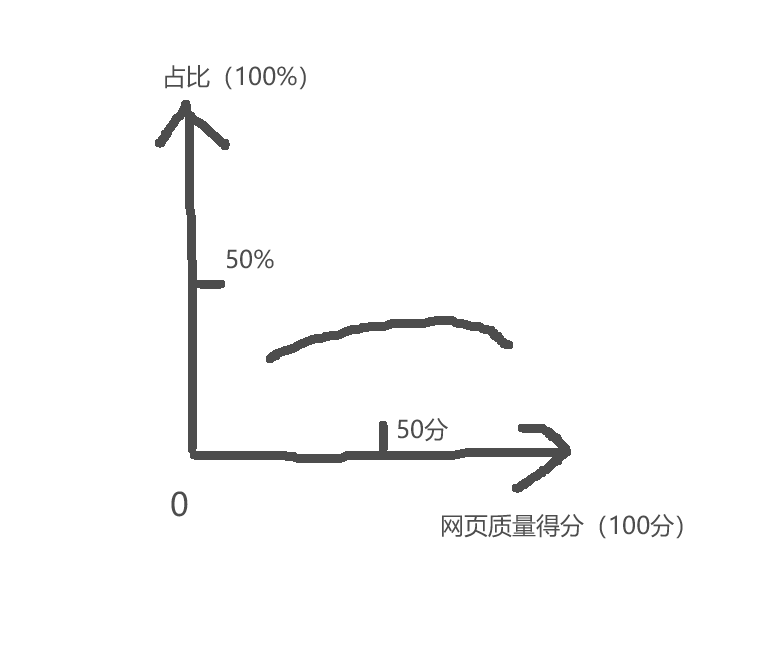
这样就可以观察大盘上文档质量的整体情况。
# 定制化分析文档质量
我们可以根据单篇文档服务质量的大盘情况,捞取质量得分偏低的文档进行进一步分析。我们可以捞取得分在【30,50】区间的文档数据,来分析得分偏低的文档是符合预期还是某些特性场景(比如超大文档)。
我们还可以调整数据统计方向,针对性考察某些特性的分布情况。假设现在针对在线表格的场景下,我们怀疑每篇表格服务质量与表格的单元格数量有关系,那么我们可以建立一个视图:
- 以表格质量得分为 y 轴
- 以表格单元格数量为 x 轴
假设我们跑出来的数据呈现如下,那么我们可以认为每篇表格服务质量与单元格数量呈明显的负相关:
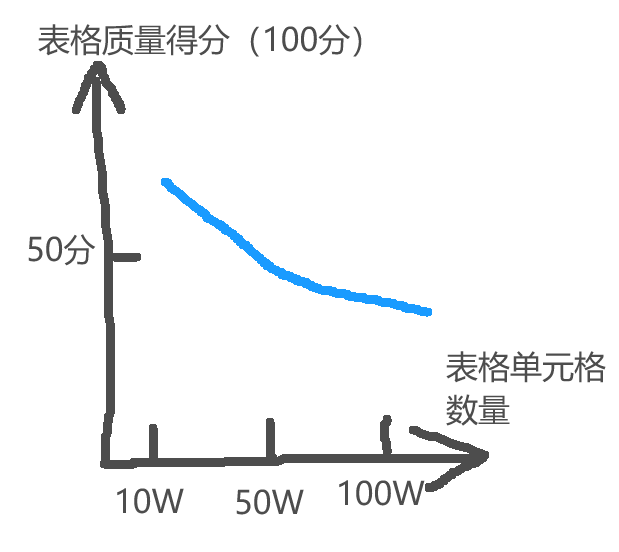
除了表格数量以外,我们还可以根据疑似有问题的特性(比如函数数量等)进行数据统计,来进行数据分析。
# 结束语
很多时候,项目小的时候我们吐槽没啥事做,项目大的时候我们又吐槽没啥办法,但其实能做的可做的还有很多。
每一个解决的问题,它都可以成为后续很多问题的助推力,去完善一个大的解决方案。多思考,多尝试,会发现还有很多东西可以学习和研究呢~
